연차가 많이 쌓이긴 개발자분들 git repository를 보면 커밋로그의 작성은 정말 체계적이다. 업무별로 딱딱 정리가 되고 적당한 타이밍에 맞춰서 커밋기록이 찍혀있다. 이것도 사실 컨벤션이라는 것이 존재하지만 git 사용 경험이 적은 분들 커밋로그 기록을 보면 뭔가의 기준이 없고 커밋을 했는데도 내용이 별로 없는 경우도 있다. 특정 업무 단위로 커밋이 작성되면 좋지만 실제로 작업하다보면 회사에서 중간에 내용을 끊고 집에 가서 작업을 해야 하는 경우도 있을 것이다. 회사에서 A기능 구현중인데 퇴근을 하고 집에서도 구현해야하는 상황에선 github로 커밋을 하고 집 PC에서 받아서 구현을 해야 한다. 그리고 집에서 기능을 작업을 하고 그것을 커밋하고 다음날 회사가서 출근하여 기능을 마무리한다. 이런 경우 커밋기록은 다음과 같이 작성될 수 있다.
A기능 회사에서 작업
A기능 집에서 작업
A기능 회사에서 결국 완성
그런데 이걸 보고 팀장님이 커밋기록이 지저분하다며 하나로 합쳐달라고 하실 수 있다. 사실 팀이나 회사마다 commit 로그 작성도 기준이 있을 것이다. 이런 기준에 맞아야 하는데 상황에 따라서는 위처럼 커밋로그를 작성할 수 밖에 없다.
git rebase
이럴 때 commit 을 재설정하는 명령어인 git rebase를 사용해보자
아래의 화면은 하나의 커밋당 하나의 파일을 추가해서 커밋을 총 4번한 상황이다. 이 상황에서 rebase를 써보려고 한다.
목적은 이 최근 3개의 커밋을 하나로 합치고 하나의 커밋로그로 만들려는 것이다. 그래서 결과적으로는 3개의 커밋작업의 파일은 유지하고 로그만 하나로 만들어서 "A기능 구현" 이라는 커밋로그 하나만 남길 것이다.
이때 사용하는 명령은 git rebase -i HEAD~3 이렇게 입력하면 된다. i 옵션은 여러개의 커밋 목록을 묶을 때 사용하고 HEAD 지점에서 3개의 커밋에 대한 rebase를 한다는 것이다. (커밋을 합치는것 뿐만 아니라 분리도 가능하다고 한다.)
이 상황에서 총 커밋이 4개므로 git rebase -i HEAD~4를 입력하면 invalid upstream 에러가 뜬다.
이 때는 git rebase -i --root 를 입력해야 초기 상태부터 하는 rebase가 가능하다.
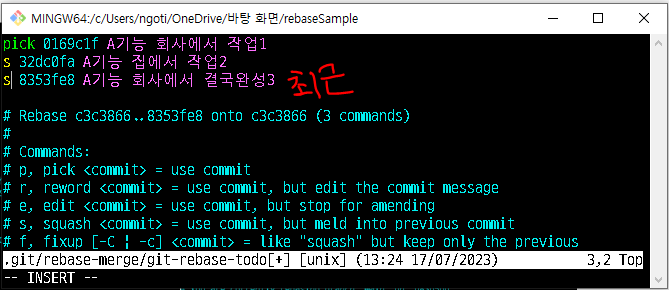
rebase 위한 창은 아래와 같다. 각 커밋에서 pick, reword, edit, squash, fixup 등의 설정을 할 수 있다.
pick은 커밋로그를 그대로 쓰겠다는 것이고
reword를 사용하면 commit 메세지를 편집할 수 있다. ( 근데 이게 써봤는데 딱히 쓸 의미가 없음 )
squash는 찌그려트린다는 말로 다른 커밋과 합친다는 말이다. ( 이전 상태로 합친다는 것 주의 )
그리고 drop이라는 것도 있어서 중간에 커밋을 삭제할 수 있다. (커밋을 삭제하면 그 커밋에 생성했던 파일이 날라가니까 주의하기)
이때 커밋로그 배치가 최근 것이 아래쪽으로 배치되는 것을 확인할 수 있다. 이제 i를 눌러서 입력모드로 진입하고 3개의 커밋중 가장 나중에 된 것 기준으로 pick을 기록하고 나머지는 s(squash)처리를 한다. ( squash가 이전 상태와 합치기 때문에 가장 나중 것을 pick으로 잡고 최근 것을 s로 지정해야 한다. )
이러면 3개의 커밋을 가장 오래전에 한 commit으로 합치겠다는 말이다.
이 상태에서 esc와 클론을 누르고 wq로 저장하면 다음단계로 진입한다.
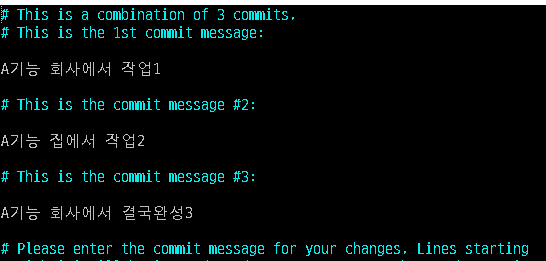
이상태는 최종 커밋메세지를 변경할 수 있는 상태이다.
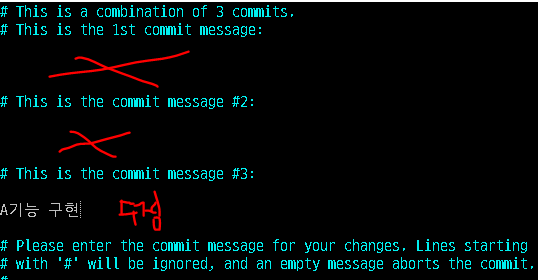
커밋 메세지 3개 중에 2개를 지우고 마지막 커밋 메세지를 알맞게 수정한다.(3개중 아무거나 하나 남기면 됨) 그리고 wq로 저장한다.
커밋메세지 수정
결과적으로 아래와 같이 커밋이 하나로 합쳐진 것을 볼 수 있다. 그리고 파일은 모두 그대로 남아있다.
파일 그대로지?
추가적인 것
만약에 rebase를 잘못 사용한 경우 git reflog로 되돌리고 아래처럼 git rebase --abort로 rebase를 제거한다.
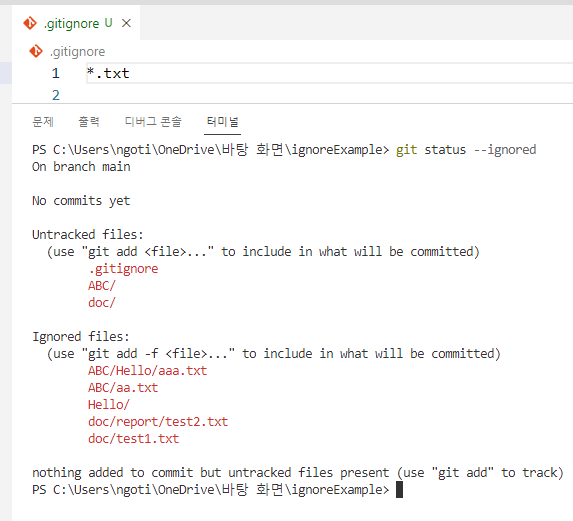
github로 작업을 할 때 주의할 점은 필요 없거나 보안측면에서 민감한 파일이 github에 올라가지 못하게 하는 것이다. 예를 들어서 팀프로젝트를 하던 중에 팀원이 이메일 인증 구현 과정에서 네이버나 구글 아이디, 비밀번호를 적어 놓은 .properties 파일을 github에 올린 경우가 있었다. 팀원은 별로 중요한 계정이 아니라고는 하지만 이것이 누군가에 의해 탈취가 되어 악용이 되는 사례가 있을 수 있다는 것을 잊어서는 안된다. 또한 누군가가 aws의 key값을 실수로 github에다가 업로드하여 그것이 탈취되어 과금폭탄을 받은 사례들이 있다. 이러한 것들을 조심해야 한다. 이런 비밀번호나 api키 값들이 main branch에 올라오게 되면 github 이메일 계정으로 이메일이 날라오는데 git gardian인가 하는데서 날라오는 것인데 이것에 대한 처리는 아직 해본적이 없긴하다.
그래서 초기에 팀원들끼리 말을 맞춰서 노출되어서 안되는 정보를 담은 config 파일들을 따로 관리를 하도록 해야 한다. 팀원들 끼리만 접근할 수 있는 구글 클라우드에 따로 저장을 해서 관리를 하던가해서 각자 작업환경에만 저장해두고 원격에는 올리면 안되는 것이다. 그리고 gitignore 셋팅은 프로젝트 초기에 바로 하는 것이 좋다. 이걸 프로젝트 진행 중간에 해버리면 이미 tracked된 파일들에 대해선 ignore 처리가 안되게 된다. 팀원들 마다의 커밋 상태가 다르기에 누군가가 중간에 ignore에 추가하더라도 merge 과정 중간에서 갑자기 노출되어서는 안되는 파일이 등장해버린다.
이러한 gitignore 파일은 이클립스로 git 작업을 하면 자동으로 만들어주는 경우가 있긴한데 그렇다하더라도 gitignore 파일 작성법은 알아야 한다. 내 config 파일이 어디에 저장할지 알고, 그리고 어떤 파일명으로 하고 어떤것을 gitignore에 추가할 줄 알고 자동화된 gitignore만 믿을 것인가? 내가 생각하는 gitignore 파일 작성 절차를 얘기해보려 한다.
.gitignore 작성절차
키워드만 입력하면 gitignore 내용을 자동으로 생성해주는 사이트를 1차적으로 이용한다.
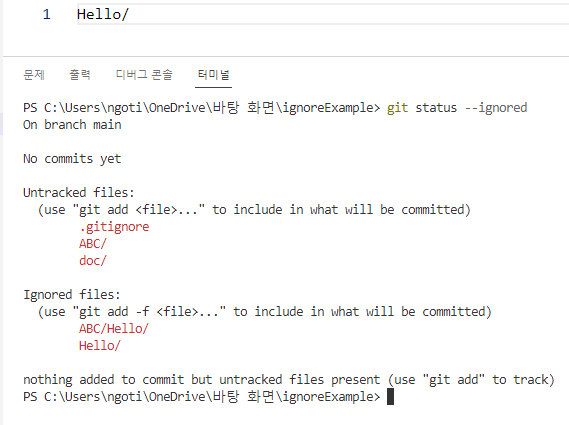
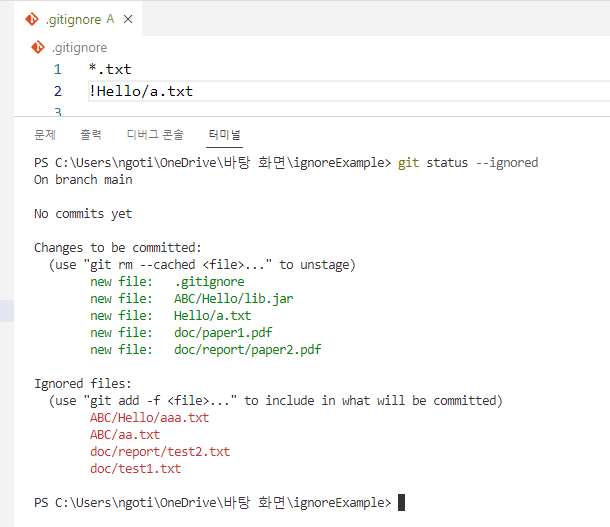
따라서 하위 폴더에 있는 Hello는 ignore하지 못하여 .gitignore 파일이 있는 위치의 Hello만 ignore한다.
/ 를 뒤에다가 붙이는 경우
해당 폴더를 하위 디렉토리까지 찾아서 ignore 해준다.
아래 그림에서는 현제 디렉토리에 있는 Hello폴더 ABC 폴더에 있는 Hello 폴더 등 모조리 찾는다.
특정 확장자 파일을 ignore 하고 싶다면?
*.txt > 이런식으로 작성한다.
와일드 카드 표시는 하위 디렉토리에 있는 파일도 모조리 포함시킨다.
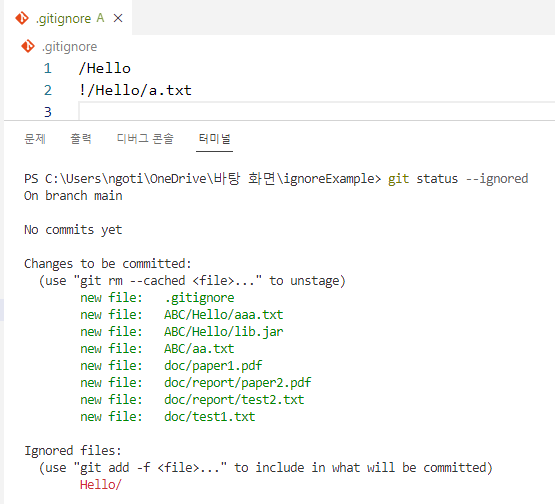
이 상황에서 특정 파일만 ignore에서 제외를 시키고 싶다면?
! 라는 키워드를 쓴다.
분명히 * 로 다 ignore 했는데 특정 파일만 !로 가르키므로써 ignore에서 제외된다.
!가 이렇게 작동함
단, ! 키워드는 폴더 채로 ignore 하고 그 안에 내용물에 대해서 ! 키워드를 작성하는 경우엔 동작하지 않는다.
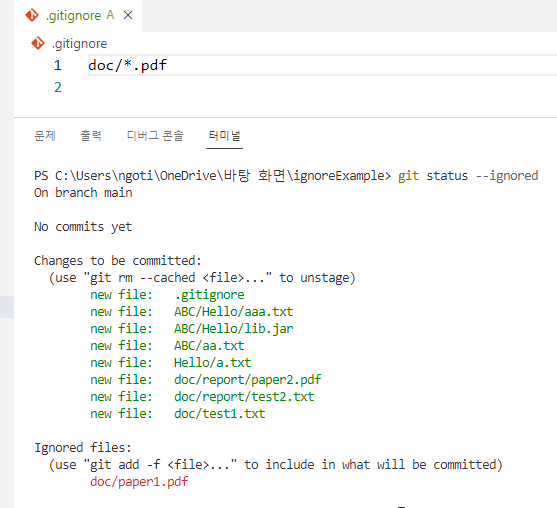
특정 폴더 안에 특정 확장자 파일을 ignore
폴더에서 depth라는 것을 고려해야 한다. 바로 밑에 있는 파일은 ignore 되지만 더 아래에 있는 doc/report/paper2.pdf는 ignore가 되지 않았다.
특정 폴더 안에 또 폴더가 있고 특정확장자 파일을 ignore
doc/**/*.pdf 와 같이 작성하면 된다. *를 두번 적으면 중간 디렉토리에 대해서 와일드 카드를 걸고 폴더가 있든 없든간에 다 잡아준다.
중간와일드
어떠한 파일을 ignore 하는 것이 좋을까?
일반적으로는 빌드되어 생성되는 target폴더나 IDE마다 프로젝트 내에서 생성되는 .setting폴더, .idea 폴더, .metadata 등의 폴더등을 ignore한다. 그리고 jar 파일도 ignore해서 작업시에 팀원들끼리 따로 공유하는 것이 좋다. 웹프로그래밍시에는 Nodejs 코드 작성시엔 env 파일을, Spring 코드 작성시에는 .properites 등의 파일을 ignore하여 관리하는 것이 좋다.
아래 그림은 내가 인터넷 어디선가에서 줍줍한 그림이다. 근데 내가 스프링의 정석 강의를 들었을 때 그림보다 이 그림이 훨씬 나은거 같아서 이걸로 정리하려고 한다. 솔직히 따로 그리긴 귀찮다. 설명은 스프링의 정석 강의에서 들은 내용으로 이야기 할 것이다. 강의에선 코드레벨까지 직접 들어가서 설명을 해주는데 음... 좀 멍때린 감이 없지 않아 있다.(이게 뭐임??하는 느낌이었다.) 그것보단 클리어하게 면접용으로 적당하게 말할 수 있는 선으로 정리하려고 한다.
Dispatcher-Servlet(디스패처 서블릿)이란?
Dispatch는 말 그대로 "보내다"라는 뜻을 가지고 있다. 이러한 의미를 내포하여 Dispatcher-Servlet은 HTTP 프로토콜로 들어오는 모든 요청을 가장 먼저 받아서 적합한 컨트롤러에 위임해주는 일종의 프론트 컨트롤러라 정의한다. 프론트 컨트롤러란 요청마다 서블릿을 만들어서 쓰지 않고 서블릿 컨테이너의 제일 앞에서 서버로 들어오는 클라이언트의 요청을 받아서 처리해주는 컨트롤러라하며 MVC 구조에서 사용되는 디자인 패턴의 하나이다. Spring MVC에서의 Dispatcher-Servlet의 사용으로 이전에 서블릿 기반의 웹 모델에서 web.xml에 URL 매핑을 위해서 일일히 등록하는 과정을 Dispatcher-Servlet이 알아서 적절한 컨트롤러로 위임해주는 구조가 되었다.
그리고 정적자원과 동적자원을 분할처리하여 요청할 컨트롤러를 먼저 찾고, 맞는 컨트롤러가 없을 땐 2차로 설정된 정적 자원을 탐색하여 처리한다. 이것은 효율적인 리소스 관리를 가능하게 한다.
디스패쳐서블릿
[ 동작방식 ]
1~2). 클라이언트로부터 요청이 오면 Dispatcher-Servlet이 요청을 받아서 HandlerMapping이 URL과 메서드를 두개를 적절하게 매핑 시켜놓은 정보를 반환한다.
3~4). HandlerAdaptor라는 친구가 중간에 끼어들어서 처리를 요청받고 그 요청을 적절한 컨트롤러에게 전달한다. ( 이후 비즈니스 로직처리~ )
5~6). 컨트롤러 실행결과를 다양한 형태로 리턴한다. ModelAndView, void, String, ResponseEntity 등 그리고 HandlerAdaptor가 그것들을 받아서 맞는 결과를 Dispatcher-Servlet에게 전해준다.
7). ViewResolver를 통해서 이름에 맞는 적절한 view를 검색하고 결과를 Dispatcher-Servlet에게 준다.
8). Dispatcher-Servlet이 해당 뷰를 호출한다.
9). JSP 파일이 응답결과를 만들고 그걸 클라이언트에게 응답한다.
그래서 최종적으로 정리하면 Dispatcher-Servlet은 요청/응답에 대한 전처리 및 컨트롤러 매핑 등 공통 로직을 수행해서 이를 통해 개발자는 비즈니스 로직에 집중한 구현이 가능하게 된다.
AWS는 Amazon Web Service의 약자로 가장 많이 사용하는 클라우드 서비스다. 공부 용도라면 Free Tier로 1년 동안은 사용할 수 있다. Free Tier이기 때문에 일부 서비스들만 무료로 사용할 수 있고 컴퓨팅 사양이 그렇게 좋지 않은 것들이라 개인적인 작업으로는 괜찮은데 팀 작업시에 메모리 부족으로 서버가 다운되는 과정이 종종 있긴했었다. 그래도 개인적인 작업 공부 용도로는 클라우드 서비스 중에 AWS 만한 것이 없다.
AWS(Amazon Web Service)에 처음 가입한지는 조금 오래됬는데 그게 몇년이 지나고 나서 새로운 이메일 계정으로 다시 만들었다. 처음 만들었던 그 당시에 체크카드로 만들었던 기억이 있는데 최근에도 그 동일한 체크카드로 다시 만들었다. AWS와 비슷한 서비스로 Oracle Cloud는 체크카드로는 가입이 안되고 신용카드로만 가입이 되서 포기한 적이 있다...
기존에는 AWS를 가입하고 root 사용자 계정으로만 로그인 했었는데 IAM 사용자로 AWS를 사용하는 방법이 있다고 한다. 루트 사용자로 인스턴스를 생성하고 IAM 사용자를 만들어서 과금이 발생할 수 있는 권한만 제거해서 AWS 계정을 이용하면 보안상의 이점이 생긴다. 그리고 추가로 다중인증(MFA : Multi-Factor Authentication)을 사용하면 스마트폰에서 OTP 관련 어플을 사용하여 인증이 가능하다.
해당 내용을 입력하면 이메일 인증 절차가 진행된다. 확인 코드를 기입하면 다음 단계로 이동한다.
가입화면
이후에 암호 입력,주소 입력, 카드정보 입력 등의 과정이 있다. 이 과정은 생략한다.
Support 플랜 중에서는 기본 지원 - 무료를 선택하고 가입을 완료 한다.
무료선택!
그리고 이제 다시 로그인 화면으로 돌아와서 로그인 폼을 보면 두 종류의 사용자가 있다는 것을 확인할 수 있다.
루트 사용자 : 최고 권한을 가진 사용자
IAM 사용자 : 루트 사용자로부터 일바 권한을 부여받은 하위 사용자들
방금 만든 계정으로는 루트 사용자 계정으로 만든 것이고 IAM 사용자는 아직 만들지 않았다.
이제 가입시 입력했던 이메일로 로그인하면 된다.
:
로그인하면 콘솔 홈으로 들어오는데 처음에 지역설정을 먼저 해야한다.
이건 AWS를 지원하는 실제 서버들이 있는 장소인데 최대한 가까운 곳인 서울로 셋팅을 해야 한다.
로그인 후
AWS 서비스
aws에서는 다양한 서비스를 지원해준다. 그 중에 대표적인 것이 EC2, S3, RDS이다.
EC2(Amazon Elastic Compute Cloud)
이건 우리가 사용할 수 있는 실제 컴퓨터라고 봐도 된다. 원하는 OS(윈도우, 리눅스), 사양을 우리가 선택할 수 있으며, 처음 인스턴스를 할당하면 아무것도 설치가 안되어 있는데 여기다가 우리가 원하는 프로그램을 설치하여 사용할 수 있다. EC2 서비스로 하여금 나 대신이 다른 사람이 컴퓨터를 관리해주는 느낌이라 보면 된다.
S3
스토리지 서비스다. 이미지나 CSS나 Javascript 파일을 전문적으로 저장하는 서비스다. 웹하드 느낌이긴하다. 단 대용량 파일들을 올리진 않는다. 그리고 너무 빈번한 Access용도로 쓰기에는 문제가 있다. CDN 자원 같은 것을 둘 때하는 서비스다.
RDS
관계형 데이터베이스를 위한 DB를 설치하여 사용할 수 있다. Oracle, MySQL, MS-SQL, PostgreSQL 등 ~
RDS 무료 티어중에 Oracle 특정 버전이 제외가 됨 > 11g 버전이 지원이 안되었음
이런 서비스들을 인스턴스라고 해서 실행의 단위가 되는 것을 만들어서 사용한다.
근데 Free Tier라고 해서 이러한 서비스를 막 여러개의 인스턴스를 생성하여 쓴다면 주의해야 한다.
서비스 사용시간 총합 월 750시간이 넘어가버리면 과금이 된다. 근데 이 750시간이 넉넉해서 인스턴스 하나를 쓰면 상관이 없는데 여러개 쓰면 문제가 된다. 예를 들어서 EC2 Free tier 가능 인스턴스라도 2개를 사용하면 서비스 사용시간이 따블로 측정되고 쉽게 750시간이 넘어가버려서 과금이 되버린다. 그래도 되도록이면 인스턴스를 여러개 만든다면 안쓰는 인스턴스는 꺼야한다.
EC2 인스턴스 생성
이제 컴퓨터 한대를 대여 받으려고 한다. 검색창에 ec2를 입력해서 EC2 서비스로 이동한다.
인스턴스 생성
인스턴스 시작 클릭
인스턴스 시작
이름 입력 > 인스턴스를 식별하기 위한 이름이다.
이름 입력
운영체제 선택 > 우분투 22.04 버전 (프리티어 되는거만 선택)
OS 선택
인스턴스 유형 > 하드웨어 사양이다.
종류가 많은데 프리티어는 t2.micro CPU하나, 메모리 1GB짜리인데 정말 Light하게 써야함
인스턴스 유형
키페어 로그인 > 계정을 만들고 로그인할 때 일종의 열쇠를 생성하는 작업이다. 이 열쇠는 공유 X
열쇠열쇠!
키 페어 생성 클릭시
이름은 아무거나 적고
RSA는 키 알고리즘 유형임 > 이걸로 택
일단은 pem으로 택 > pem이라도 ppk로 바꿀 수 있다.
생성하면 파일 하나가 만들어지는데 이건 잃어버리면 안된다.
키 보관은 무난하게 .ssh 폴더 만들어서 그 안에 넣는 방법이 있다. 근데 나는 바탕화면 폴더에다가 저장한다.. 그냥 은근히 키 찾을 일이 많아서 보이는 곳에 둠(귀찮아서...)
보안그룹 규칙
편집 버튼을 누르면 펼쳐진다.
넽워크설정
이러한 보안그룹으로 방화벽 설정이 가능하다. 보안 그룹 이름을 적당한걸 적는다. 그리고 default로 ssh 보안 그룹이 지정이 되어 있는데 보안 그룹 규칙 추가 버튼을 눌러서 새롭게 추가한다. ( 근데 이게 지금 설정하지 않더라도 나중에 보안그룹을 따로 추가할 수 있다. )
HTTP에 대하여 소스 유형을 위치 무관으로 하여 어디서든 접속할 수 있도록하게 보안 그룹 규칙 2를 지정한다.
스토리지 구성
프리티어는 최대 30기가까지 사용가능하니까 최대치로 설정한다.
인스턴스 시작
왼쪽 사이드탭에 인스턴스에 EC2 인스턴스가 추가되고 실행중으로 표시가 된다.
저기 보면 실행중으로 표시되는데 이 컴퓨터는 내가 멈추거나 제거하든지, 리부트 하든지의 작업을 할 수 있다.
여기까지 인스턴스 생성까지의 내용이다. 분량이 너무 길어서 다음 글에 이어서 작성하려고 한다. 현재까지의 내용들은 수업 때 녹화한 것들을 기반으로 작성하고 있다. 수업 이전에 내가 혼자서 진행한 부분이 있지만 뭔가 설명을 같이 듣고 다시 정리하니까 이해하기가 쉬워진다. 아무튼 다음 글에 이어서..
이전부터 블로그에 기술적인 글을 꾸준히 작성하고 싶었으나 내용정리가 안되고 학원에 다니느라 뭔가 시간적인 여유가 없었다. 다행이도 꾸준히 어딘가에 기록은 해놓아서 맘먹으면 지금도 수업 때 배운 내용을 복원시켜서 작성이 가능하다. 그래서 이제는 뭔가 여유가 생긴 것 같아서 본격적으로 블로그 기술 정리를 하려고 한다. 이것저것 카테고리는 많이 만들어놨으나... 글이 0개 1개 짜리 이런걸 보고 있노라면 조금은 부끄럽다. ㅎ
학원에서 배웠을 때 중요하게 느꼈던 것들 혹은 배우지 않았던 것들을 추가적으로 기록해야 하는데 최소 각 카테고리 10개씩 정도는 계획하고 있다. AWS쪽이나 스프링 채팅쪽은 따로 녹화를 해놔서 보면서 정리를 할건데 추가적으로 검색해서 채워넣어야 할 내용들이 많다. 학원에서 배운 내용들이 전체적으로 정리가 되면 몇개월 후엔 AI쪽 기술도 정리하려 한다. pytorch를 사용해서 aws 람다로 서비스 하는 것을 이전부터 해보고 싶었는데 지금은 꿈도 꾸지 못하고 있다. 파이썬 쪽도 다시 공부를 해야겠다고 느낀게 프로젝트 때 데이터 크롤링 할 때 느끼긴 했다. 빠르게 구현하기 편한게 파이썬 만한게 없다. 자바도 물론 jsoup으로 크롤링이 가능한데 dto 정의하고 프로젝트 셋팅하는게 여간 귀찮은게 아니다. 실제 실무에서도 파이썬을 써야하는 일이 많을테니 최대한 익숙해지려 한다.
왜 Thymeleaf를 써야하는지는 이전 글의 jsp 설정에서 봤듯이 STS4에서 jsp 셋팅을 기본으로 지원을 하지 않는다는 점이다. 반면에 Thymeleaf는 초기 프로젝트 설정에서 Dependency로 Thymeleaf만 추가해도 셋팅이 된다. 인프런에 있는 많은 강의에서도 대부분 부트 입문자에게 Thymeleaf쪽을 공부하는 것을 추천한다. Thymeleaf는 JSP와 비슷한 것이 많은데 추가적으로 몇가지 편리한 기능들이 추가되어 JSP에서는 불편했던 것들이 Thymeleaf에서는 좀 더 작업하기 편한 것들이 있다. 무조건 Thymeleaf만을 쓰라는 것은 아니다. FreeMarker나 Groovy, Mustache 등의 템플릿 엔진도 있다. 나중에 기회가 되면 이러한 것들도 공부해보고 싶긴하다.
Thymeleaf 플러그인 설치
설치해
STS4에서 thymeleaf 관련 속성들의 인텔리센스는 위의 플러그인 설치로 인해 가능해진다. 참고하기
설치되면 이게 가능
프로젝트 셋팅
프로젝트 생성
* STS4 > New 탭 > Spring Start Project
- Name > boot-thymeleaf
- Type > Maven
- Packaging > Jar
- Java Version > 11
- Language > Java
- Group > com.test.thymeleaf
- Artifcat > boot-mybatis
- Package > com.test.thymeleaf
- Spring boot version > 2.7.13
* Dependency
- Spring Web
- Oracle Driver
- MyBatis Framework
- Lombok
- Thymeleaf
- Spring Boot DevTools
설정파일 셋팅 > application.properties
classpath이건 스프링과 동일하게 기본적으로 src/main/resources 이다.
작업할 땐 spring.thymeleaf.cache=false
# 서버 포트 번호
server.port = 8092
# JSP View Resoler, webapp, WEB-INF 폴더가 없음
spring.mvc.view.prefix=/WEB-INF/views/
spring.mvc.view.suffix=.jsp
# HikariCP settings
spring.datasource.hikari.minimumIdle=5
spring.datasource.hikari.maximumPoolSize=20
spring.datasource.hikari.idleTimeout=30000
spring.datasource.hikari.maxLifetime=2000000
spring.datasource.hikari.connectionTimeout=30000
spring.datasource.driver-class-name=oracle.jdbc.OracleDriver
spring.datasource.url=jdbc:oracle:thin:@localhost:1521:xe
spring.datasource.username=hr
spring.datasource.password=java1234
#Thymeleaf
spring.thymeleaf.enabled=true
spring.thymeleaf.prefix=classpath:/templates/
spring.thymeleaf.suffix=.html
# 이전에 내용을 캐싱시켜준거 보여주는데 속도 빠르게 해주는데
# 개발할때는 고친게 눈에 바로 보여야 한다. 캐시 활성화 끈다.
spring.thymeleaf.cache=false
spring.thymeleaf.encoding=UTF-8
# 이설정을 하면 mybatis 다루는데 필요한 설정이 가능
mybatis.config-location=classpath:mybatis-config.xml
@Controller
public class ThymeleafController {
@GetMapping("/m1")
public void m1() {
// 요청 메소드의 반환값 > void > m1.jsp 호출
// 요청 메소드의 반환값 > void > m1.html 호출
System.out.println("m1");
}
// 위와 아래는 동일한 표현이다. > void 반환값, String 반환값
/*@GetMapping("/m1")
public String m1() {
System.out.println("m1");
return "m1"; // 이것도 마찬가지로 m1.html 호출이다.
}*/
}
★★★ Thymeleaf Standard Expression
1. Variable Expression, 변수 표현식
- ${}
- 컨트롤러 > 전달된 값 > 출력하는 역할
* 우리가 쓰던 EL과 비슷하다!
2. Selection Variable Expression, 선택 변수 표현식
- *{}
- 객체/맵 프로퍼티 > 출력
- th:object 속성과 같이 사용
3. Message Expression, 메세지 표현식
- #{}
- 스프링 메세지 > 전용 출력
4. Link URL Expression, 링크 주소 표현식
` @{}
- 링크의 URL > 전용 출력
5. Fragment Expression, 조각 표현식
- ~{}
- 조각 페이지 삽입(include 지시자 or 타일즈 > 유사 )
- 타임리프 > th:XXX 옆엔 속성이다.
"/m3" Controller 부분
기존 스프링과 동일 model에 담아서 전송, map을 사용해도 되고 int나 String으로 넣어도 model에 넣는데 차이 없음
@GetMapping("/m3")
public String m3(Model model) {
int num = mapper.getNum();
String txt = mapper.getTxt();
BoardDTO dto = mapper.getDTO();
Map<String, String> map = new HashMap<String, String>();
map.put("dog","강아지");
map.put("cat","고양이");
model.addAttribute("num", num);
model.addAttribute("txt", txt);
model.addAttribute("now", Calendar.getInstance());
model.addAttribute("dto", dto);
model.addAttribute("map", map);
return "m3";
}